Eigen 与 CMSIS-DSP 在 Cortex-M4F 上的矩阵性能实测
前言
在嵌入式 MCU 开发中,矩阵运算是处理信号处理、控制算法及姿态解算等任务的核心。如何在高资源受约束的硬件上实现更高效的矩阵计算,始终是开发者关注的焦点。
在 C 语言生态中,CMSIS-DSP 库作为 ARM 官方提供的标准,针对 Cortex-M 系列内核进行了深度指令级优化(如 SIMD、FPU 加速);而在 C++ 领域,Eigen 则以其高度抽象的模板元编程技术和优雅的语法享誉业界。那么,当“极致的硬件优化”遇上“高度的代码抽象”,两者在性能表现上孰优孰劣?本文旨在通过在 Cortex-M4 平台上的实测数据,深度对比这两个设计哲学迥异的数学库,探讨它们在实际嵌入式场景下的效率差异。
实验环境
- 硬件平台:STM32F407ZGT6(Cortex-M4F)
- 编译器:ST ARM Clang 19.1.6+st.10
- 数学库版本:Eigen 3.4.90 / CMSIS-DSP v1.17.0-4-g334ed5891
内核视角
Cortex-M4F 具备单精度 FPU,并支持以 MAC 为代表的 DSP 指令路径。放到矩阵运算语境中,两种路线的差异会非常直观:
- CMSIS-DSP 的
arm_mat_mult_f32更接近“人工精调算子”,依赖手写内核、循环展开与寄存器级调度。 - Eigen 更接近“模板表达 + 编译器兑现”,依赖模板展开后由编译器完成内联、常量传播与指令选择。
因此,这组基准测试本质上是在比较手工优化上限与编译器自动优化上限在 Cortex-M4F 上的分界点。
公平性控制
- 两侧矩阵在内存里的存放顺序统一行主序
- 输入/输出矩阵全静态分配,避免动态分配抖动
- DWT 周期计数,扣除计时本底
- 测量关键区使用临界区,降低中断干扰
核心计算
矩阵生成
矩阵样本使用线性同余发生器(LCG)state = state * 1664525 + 1013904223 生成伪随机序列,再取高 24 bit 映射到 [-1, 1) 浮点区间。为保证求逆测试稳定可执行,FillInvertibleMatrix 会在随机矩阵基础上对角线加 n,提升对角占优特性,降低奇异矩阵出现概率。
std::uint32_t LcgRng::NextU32()
{
state_ = state_ * 1664525U + 1013904223U;
return state_;
}
float LcgRng::NextFloatSigned()
{
const std::uint32_t u24 = (NextU32() >> 8U) & 0x00FFFFFFU;
const float unit = static_cast<float>(u24) * (1.0F / 16777216.0F);
return (unit * 2.0F) - 1.0F; // [-1, 1)
}
void LcgRng::FillMatrix(float* dst, std::size_t n)
{
const std::size_t elements = n * n;
for (std::size_t i = 0; i < elements; ++i)
{
dst[i] = NextFloatSigned();
}
}
void LcgRng::FillInvertibleMatrix(float* dst, std::size_t n)
{
FillMatrix(dst, n);
for (std::size_t row = 0; row < n; ++row)
{
dst[row * n + row] += static_cast<float>(n); // 对角增强,提升可逆性
}
}
Eigen 实现
本文构建统一使用 EIGEN_NO_DEBUG 与 EIGEN_MPL2_ONLY,避免调试断言与无关特性对结果造成干扰。
// 针对不同的矩阵大小,3/4/6/8/10/16/32 走 fixed, 64 走 dynamic
template <int N>
void EigenMultiplyFixed(const float* a, const float* b, float* out)
{
using MatrixType = Eigen::Matrix<float, N, N, Eigen::RowMajor>;
const Eigen::Map<const MatrixType> matrix_a(a);
const Eigen::Map<const MatrixType> matrix_b(b);
Eigen::Map<MatrixType> matrix_out(out);
matrix_out.noalias() = matrix_a * matrix_b;
}
void EigenMultiplyDynamic(std::size_t n, const float* a, const float* b, float* out)
{
using DynamicMatrix = Eigen::Matrix<float, Eigen::Dynamic, Eigen::Dynamic, Eigen::RowMajor>;
const Eigen::Map<const DynamicMatrix> matrix_a(a, static_cast<Eigen::Index>(n),
static_cast<Eigen::Index>(n));
const Eigen::Map<const DynamicMatrix> matrix_b(b, static_cast<Eigen::Index>(n),
static_cast<Eigen::Index>(n));
Eigen::Map<DynamicMatrix> matrix_out(out, static_cast<Eigen::Index>(n),
static_cast<Eigen::Index>(n));
matrix_out = matrix_a.lazyProduct(matrix_b);
}
template <int N>
void EigenInverseFixed(const float* src, float* out)
{
using MatrixType = Eigen::Matrix<float, N, N, Eigen::RowMajor>;
const Eigen::Map<const MatrixType> matrix_src(src);
Eigen::Map<MatrixType> matrix_out(out);
matrix_out = matrix_src.inverse();
}CMSIS-DSP 实现
CMSIS-DSP 使用了 ARM_MATH_LOOPUNROLL 宏,以便在 M4F 平台上更激进地展开关键循环。
arm_status RunCmsisMultiply(std::size_t n, const float* a, const float* b, float* out)
{
arm_matrix_instance_f32 matrix_a{};
arm_matrix_instance_f32 matrix_b{};
arm_matrix_instance_f32 matrix_out{};
arm_mat_init_f32(&matrix_a, static_cast<std::uint16_t>(n), static_cast<std::uint16_t>(n),
const_cast<float*>(a));
arm_mat_init_f32(&matrix_b, static_cast<std::uint16_t>(n), static_cast<std::uint16_t>(n),
const_cast<float*>(b));
arm_mat_init_f32(&matrix_out, static_cast<std::uint16_t>(n),
static_cast<std::uint16_t>(n), out);
return arm_mat_mult_f32(&matrix_a, &matrix_b, &matrix_out);
}
arm_status RunCmsisInverse(std::size_t n, float* src_mutable, float* out)
{
arm_matrix_instance_f32 matrix_src{};
arm_matrix_instance_f32 matrix_out{};
arm_mat_init_f32(&matrix_src, static_cast<std::uint16_t>(n),
static_cast<std::uint16_t>(n), src_mutable);
arm_mat_init_f32(&matrix_out, static_cast<std::uint16_t>(n),
static_cast<std::uint16_t>(n), out);
return arm_mat_inverse_f32(&matrix_src, &matrix_out);
}
反汇编抽样验证
为了避免只看跑分结论,这里补一段与基线一致构建(C1)的反汇编抽样。
编译参数(摘录)
-O3 -flto -mcpu=cortex-m4 -mfpu=fpv4-sp-d16 -mfloat-abi=hard -DNDEBUG
抽样结果
- 实验代码中
BenchmarkMath::RunEigenMultiply和动态乘法路径的gebp_kernel里,主序列是vmul.f32 + vadd.f32 - 在 Eigen 主热点路径中,没有看到直接的
vmla.f32指令 fmaf函数本身是vfma.f32(地址0x080007fe),但在这个构建里属于辅助调用路径,而不是主展开内核形态- 指令计数(同一抽样范围):
RunEigenMultiply:vmul.f32=191、vadd.f32=159、vfma.f32=0、vmla.f32=0gebp_kernel:vmul.f32=45、vadd.f32=49、vfma.f32=0、vmla.f32=0
这意味着本文结论应理解为:在当前编译器版本和参数下,Eigen 的矩阵乘法主要依赖编译器生成的 vmul+vadd 序列,而不是稳定的 vmla/vfma 直出。这也正是 ARM Clang 版本变化会带来波动的原因之一。
编译条件
| 用途 | 编译参数 |
|---|---|
| 基线发布 | -O3 -flto -DNDEBUG |
| 去跨单元优化 | -O3 -DNDEBUG(no LTO) |
| 激进浮点优化 | -O3 -flto -ffast-math -DNDEBUG |
| 禁循环展开 | -O3 -flto -fno-unroll-loops -DNDEBUG |
| 调试友好 | -Og -g -flto -DNDEBUG |
| 尺寸极限 | -Oz -flto -DNDEBUG |
-Ofast -flto -DNDEBUG与-O3 -flto -ffast-math -DNDEBUG现象几乎重合,因此没有纳入统计
可视化
测试流程
flowchart LR A[编译条件组合] --> B[矩阵尺寸集合] B --> C[矩阵数据生成] C --> D[Warm-up 预热] D --> E[Eigen DWT 计时] D --> F[CMSIS-DSP DWT 计时] E --> G[误差校验与异常剔除] F --> G G --> H[3轮汇总与几何均值] H --> I[可视化与拐点分析]
基线绝对周期图(-O3 -flto -DNDEBUG)
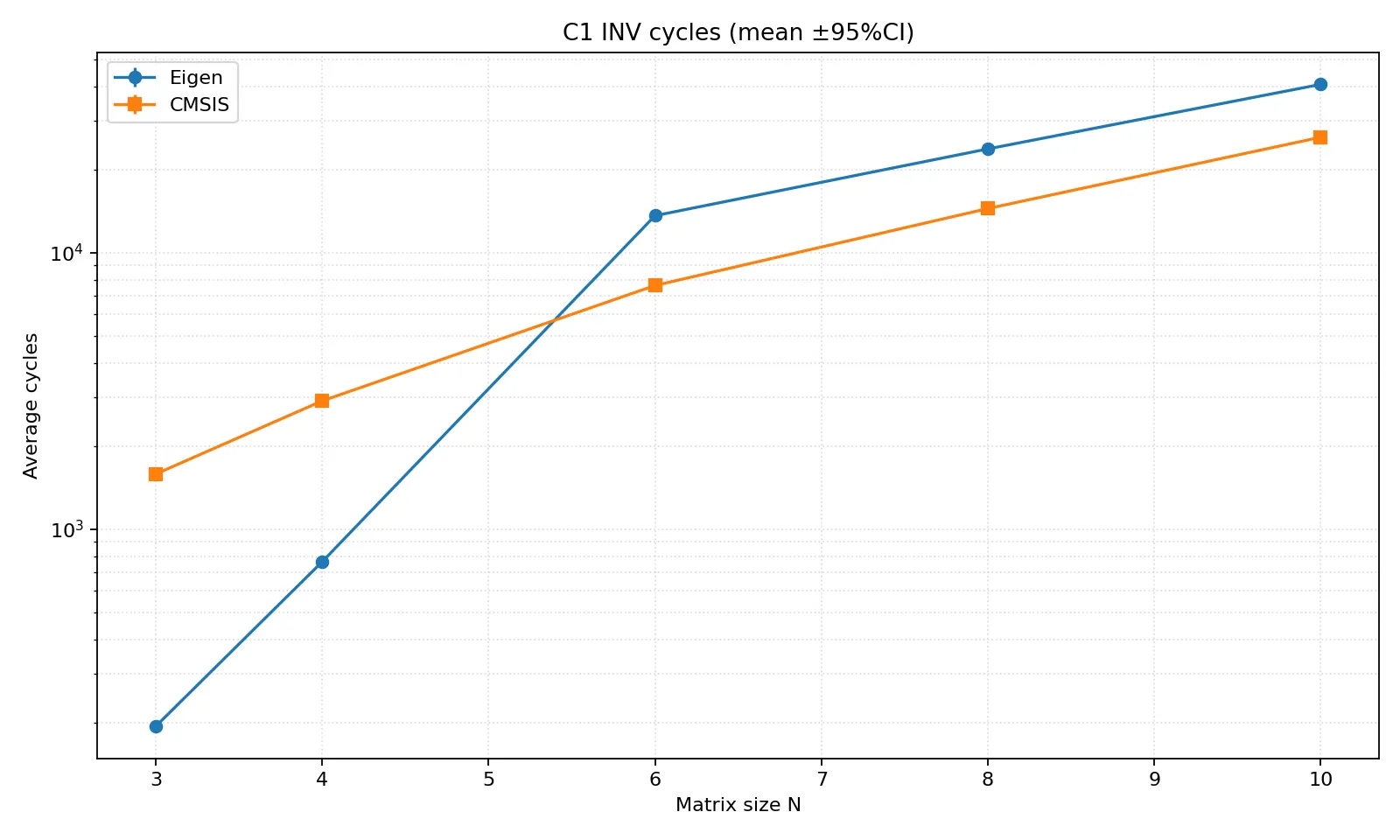
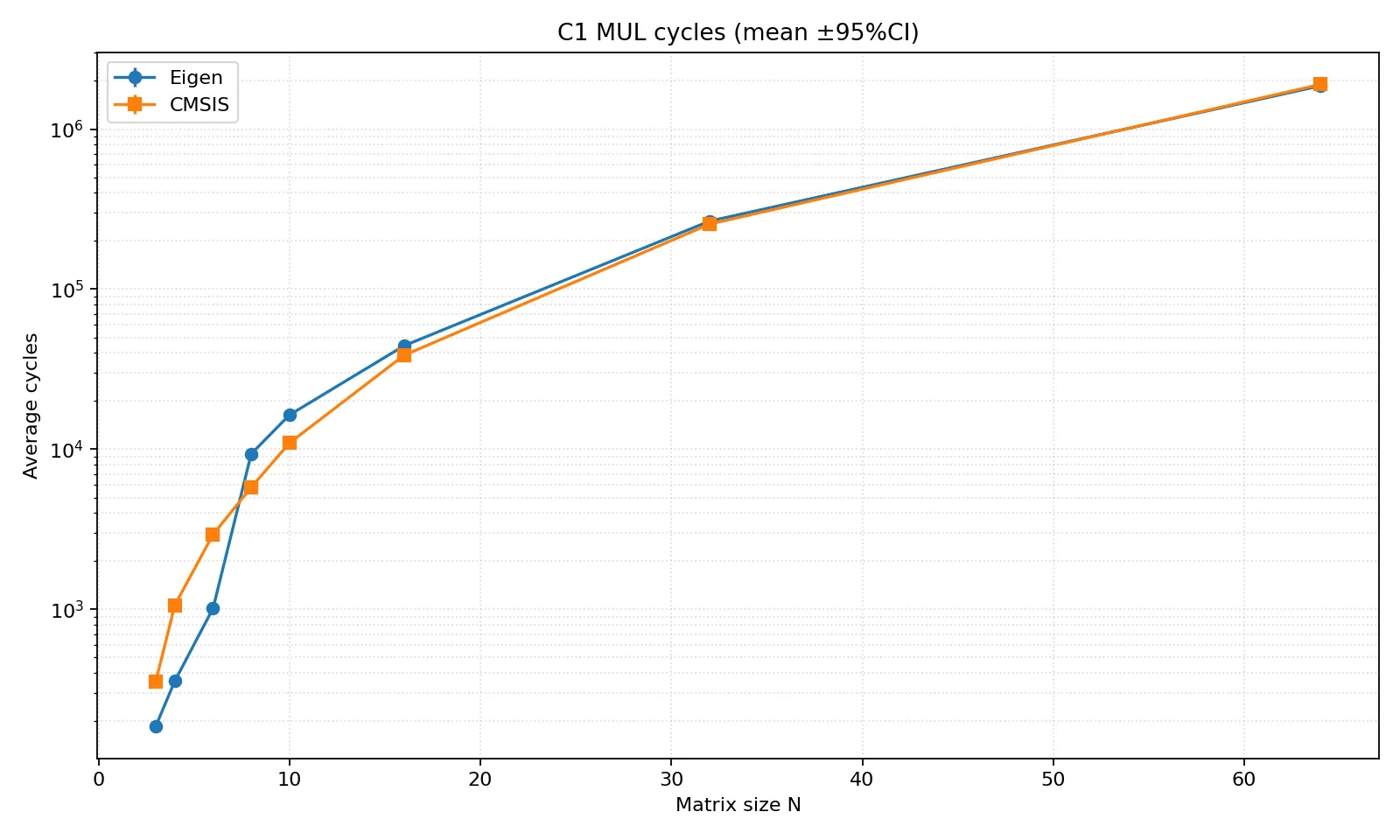
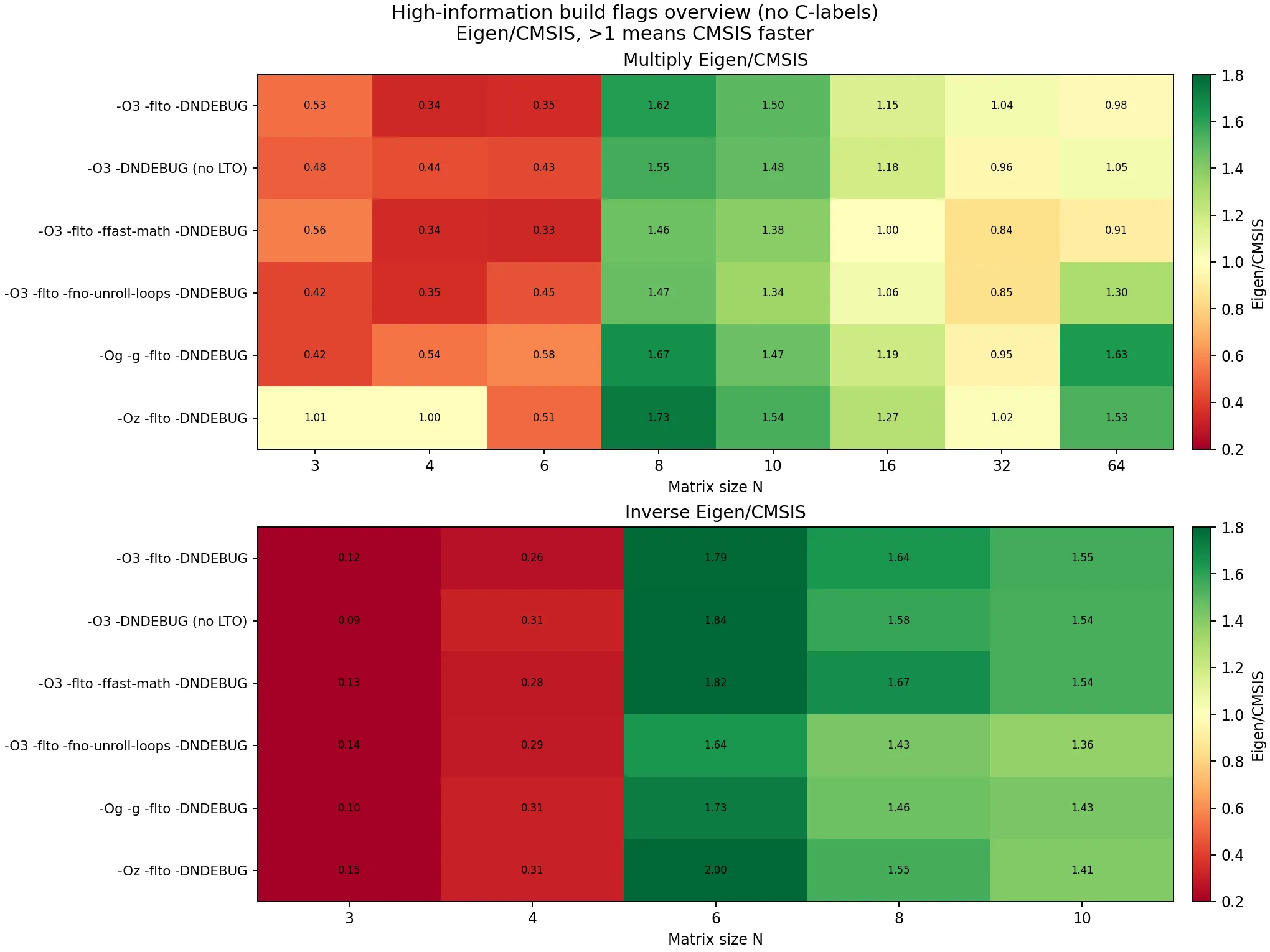
单图概览
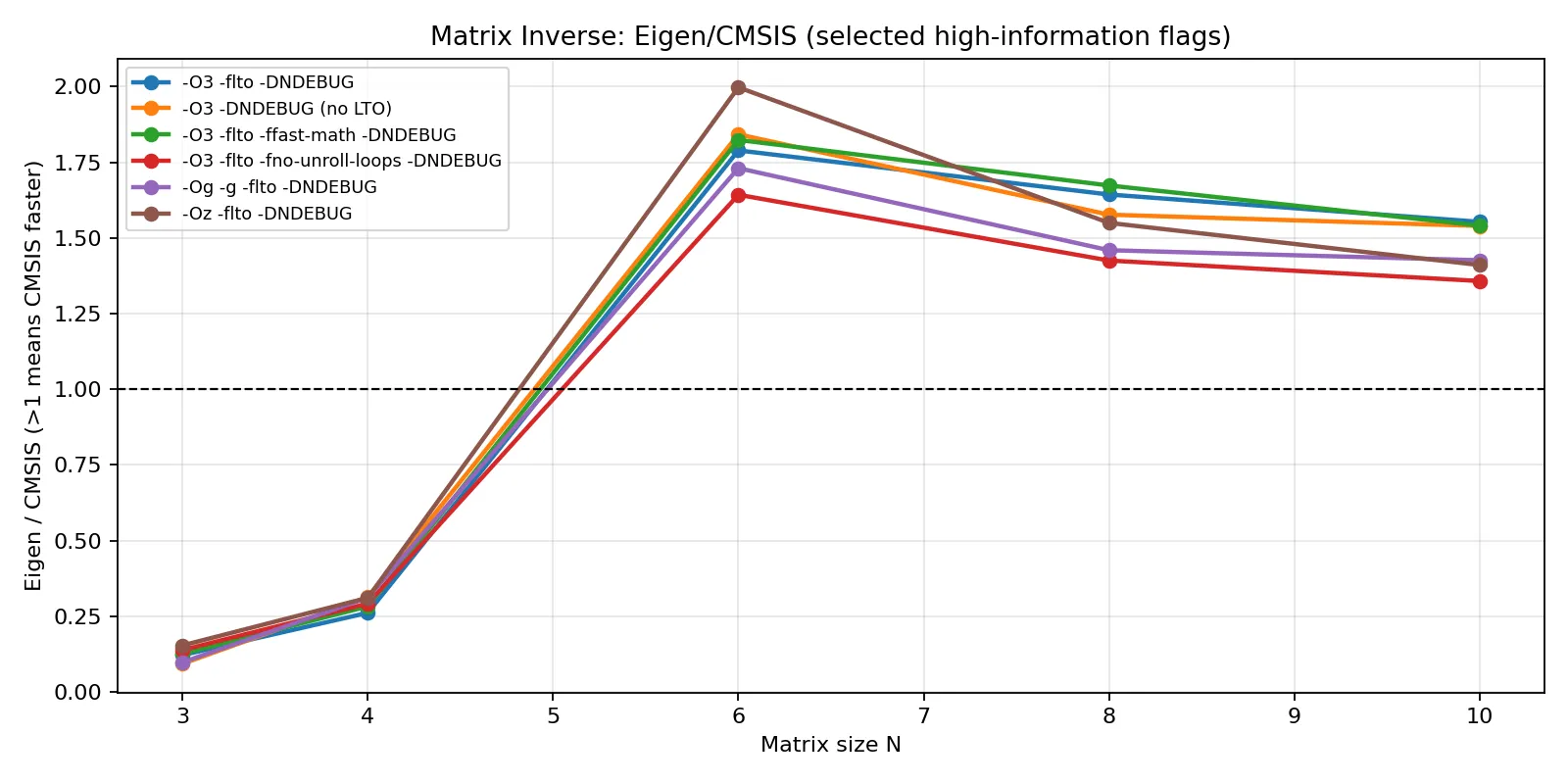
不同编译条件下的矩阵求逆曲线(Eigen/CMSIS)
不同编译条件下的矩阵乘法曲线(Eigen/CMSIS)
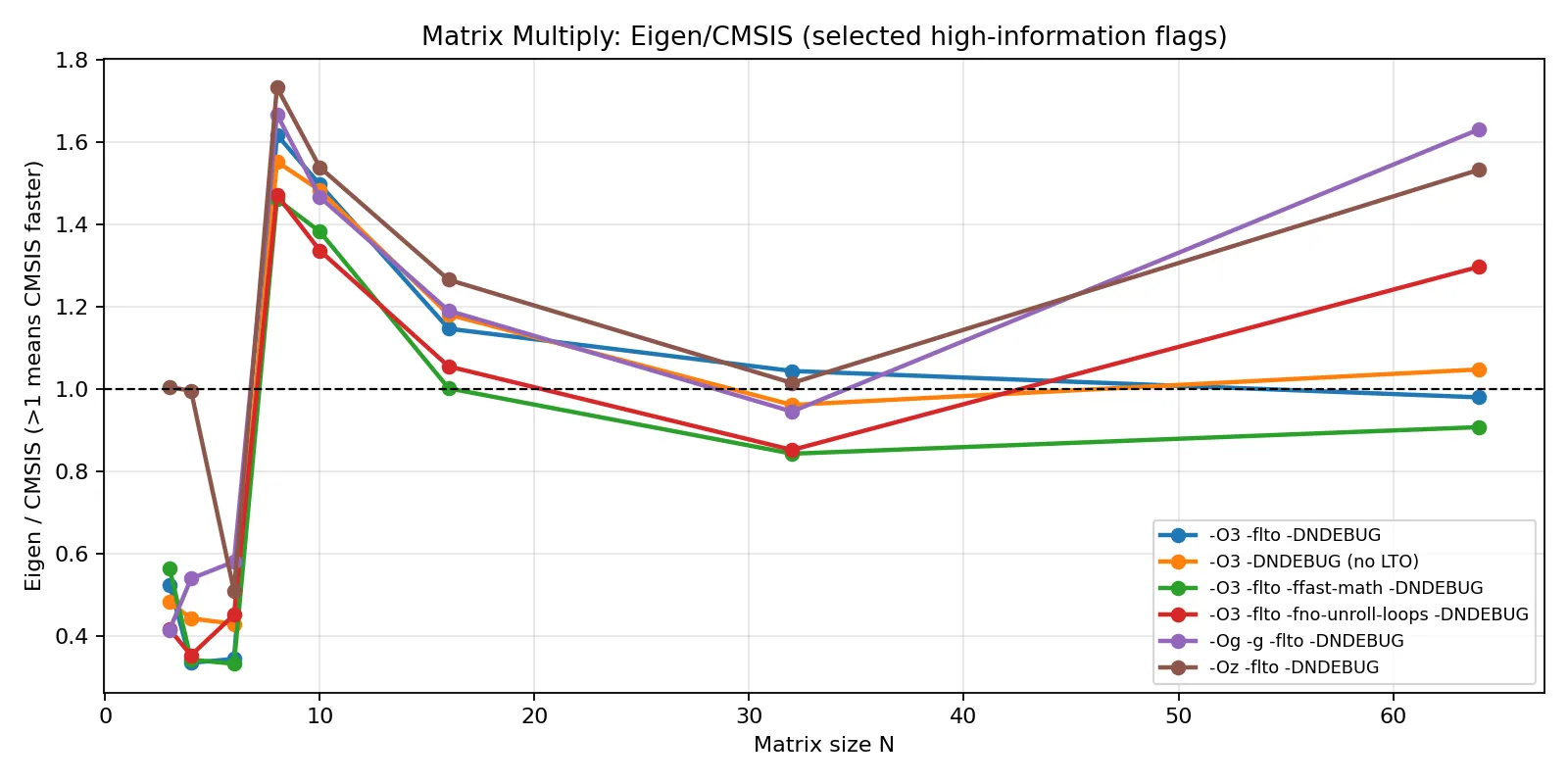
总结
3 轮汇总后可以得到一个稳定结论:主拐点出现在 N = 8 附近(-Oz 例外更早,在 N = 3 即接近持平)。
| 编译参数 | 几何均值 (E/C) | 乘法首次达到 E/C >= 1 的尺寸 |
|---|---|---|
-O3 -flto -DNDEBUG | 0.754 | 8 |
-O3 -DNDEBUG(no LTO) | 0.769 | 8 |
-O3 -flto -ffast-math -DNDEBUG | 0.731 | 8 |
-O3 -flto -fno-unroll-loops -DNDEBUG | 0.740 | 8 |
-Og -g -flto -DNDEBUG | 0.810 | 8 |
-Oz -flto -DNDEBUG | 0.957 | 3 |
可见:在 Cortex-M4F 上,Eigen 与 CMSIS-DSP 的优劣主要由矩阵规模与优化目标共同决定。对于 N < 8 的微小矩阵,Eigen 更容易依靠模板展开、全内联和常量传播摊薄调用与索引开销;当 N >= 8 进入常规矩阵区间后,CMSIS-DSP 的内核级调度与手写算子优势开始稳定体现,且在求逆场景中更明显;而在 -Oz 这类尺寸优先策略下,两者差距会显著收敛,本质上是通过牺牲峰值性能换取代码体积收益。落到算法选型上,可优先将姿态解算、标定这类 3x3~6x6 小矩阵场景交给 Eigen,将中等状态量 EKF、RLS 等 8 阶以上且求逆频繁的场景交给 CMSIS-DSP;若同一工程同时覆盖两类热点,按路径混用并在目标编译参数下复测通常更稳妥。
One More Thing: 产物大小
对比口径
- 固定编译参数:
-O3 -flto -DNDEBUG(同一工程、同一链接脚本) - 仅切换两个开关:
BENCHMARK_ENABLE_EIGEN、BENCHMARK_ENABLE_CMSIS .text用于观察代码体积变化Flash 估算 = .text + .rodata + .dataRAM 静态占用 = .data + .bss- 统计工具:
starm-size -A
实验结果
| 组合 | Eigen | CMSIS-DSP | .text (B) | Flash 估算 (B) | RAM 静态占用 (B) | 相对 baseline 增量(Flash / RAM) |
|---|---|---|---|---|---|---|
| baseline(两库都关闭) | OFF | OFF | 59264 | 60116 | 63628 | 0 / 0 |
| 仅 Eigen | ON | OFF | 90528 | 91380 | 80032 | +31264 / +16404 |
| 仅 CMSIS-DSP | OFF | ON | 66128 | 66980 | 96396 | +6864 / +32768 |
| Eigen + CMSIS-DSP | ON | ON | 99808 | 100660 | 112800 | +40544 / +49172 |
这个口径下可见,Eigen 在本项目里的主要开销更偏向 Flash(模板实例化导致 .text 增量较大),CMSIS-DSP 的主要开销更偏向静态 RAM(本工程配置下 .bss 增量更明显)。两库同时启用时,占用接近两者增量叠加。
这里的 RAM 增量是“当前 benchmark 固件实现”的总增量,包含库函数可达后被保留的静态工作缓冲区,不等同于“库源码本体独立打包大小”。